Context Reasoning Attention Network for Image Super-Resolution
International Conference on Computer Vision (ICCV), 2021.
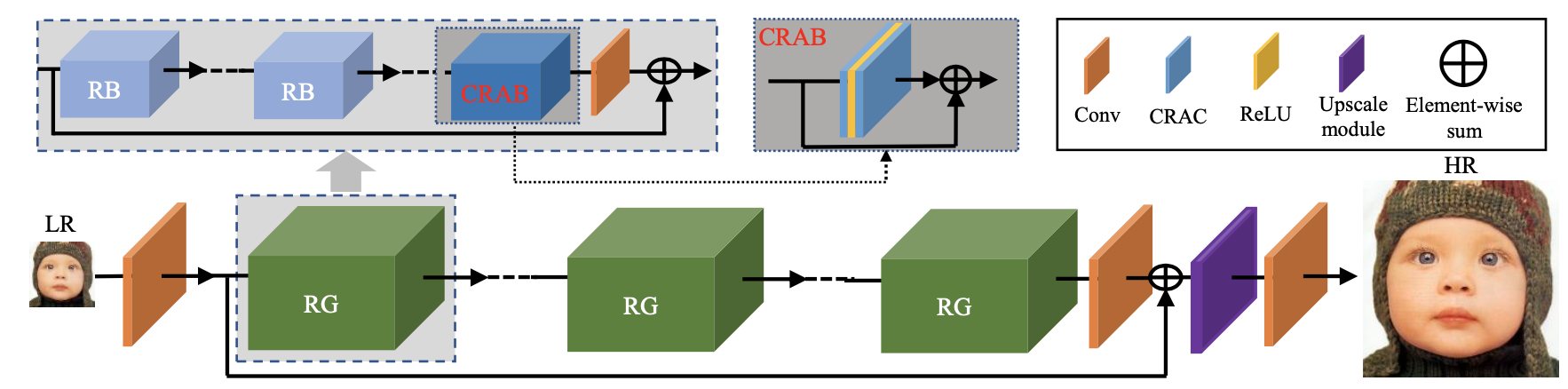
Deep convolutional neural networks (CNNs) are achiev- ing great successes for image super-resolution (SR), where global context is crucial for accurate restoration. However, the basic convolutional layer in CNNs is designed to extract local patterns, lacking the ability to model global context. With global context information, lots of efforts have been devoted to augmenting SR networks, especially by global feature interaction methods. These works incorporate the global context into local feature representation. However, recent advances in neuroscience show that it is necessary for the neurons to dynamically modulate their functions ac- cording to context, which is neglected in most CNN based SR methods. Motivated by those observations and analyses, we propose context reasoning attention network (CRAN) to modulate the convolution kernel according to the global context adaptively. Specifically, we extract global context descriptors, which are further enhanced with semantic rea- soning. Channel and spatial interactions are then intro- duced to generate context reasoning attention mask, which is applied to modify the convolution kernel adaptively. Such a modulated convolution layer is utilized as basic compo- nent to build the blocks and networks. Extensive exper- iments on benchmark datasets with multiple degradation models show that CRAN obtains superior results and favor- able trade-off between performance and model complexity.