Culling for Extreme-Scale Segmentation Volumes: A Hybrid Deterministic and Probabilistic Approach
IEEE Transactions on Visualization and Computer Graphics (Proceedings IEEE Scientific Visualization 2018), 2018.
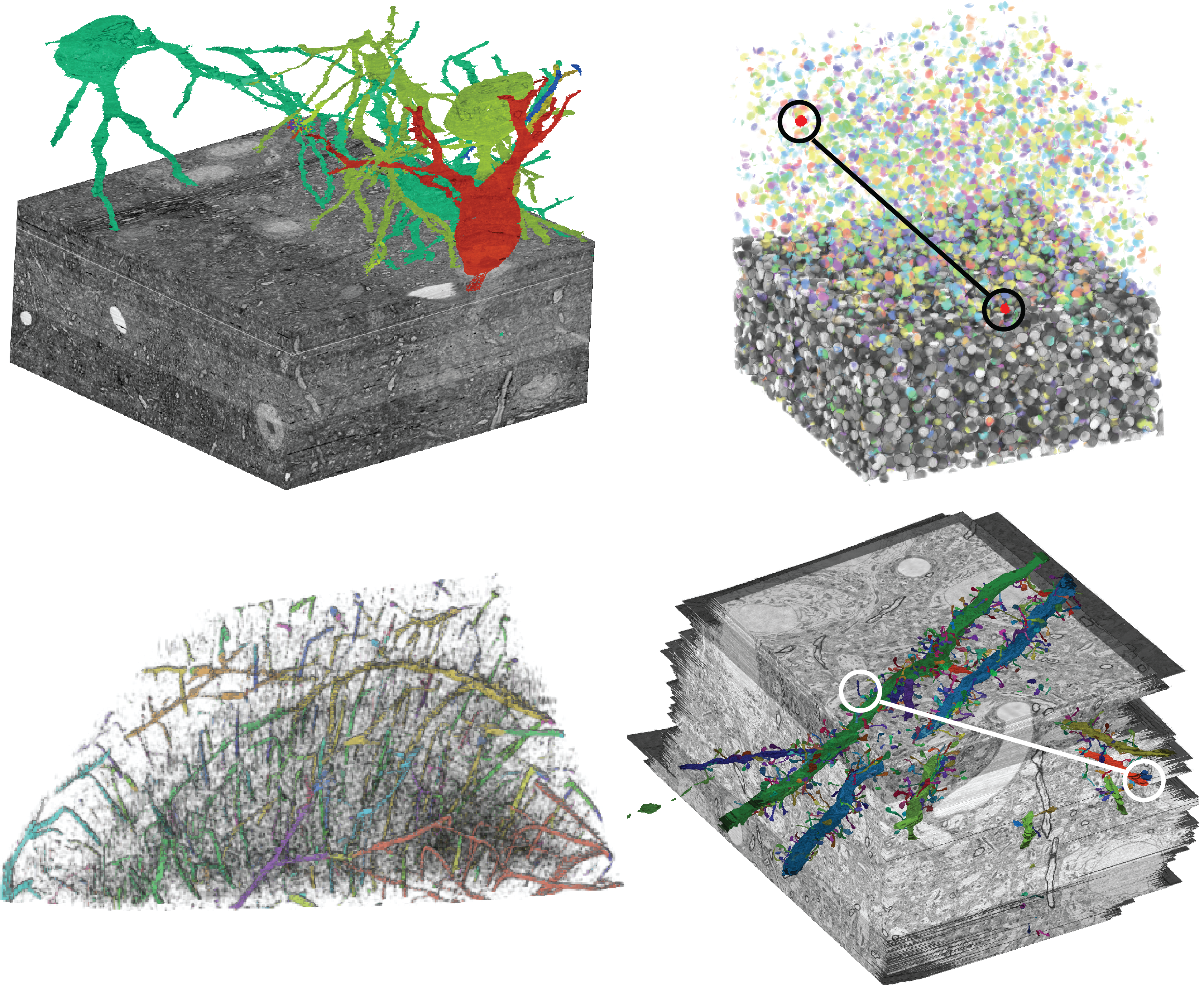
With the rapid increase in raw volume data sizes, such as terabyte-sized microscopy volumes, the corresponding segmentation label volumes have become extremely large as well. We focus on integer label data, whose efficient representation in memory, as well as fast random data access, pose an even greater challenge than the raw image data. Often, it is crucial to be able to rapidly identify which segments are located where, whether for empty space skipping for fast rendering, or for spatial proximity queries. We refer to this process as culling. In order to enable efficient culling of millions of labeled segments, we present a novel hybrid approach that combines deterministic and probabilistic representations of label data in a data-adaptive hierarchical data structure that we call the label list tree. In each node, we adaptively encode label data using either a probabilistic constant-time access representation for fast conservative culling, or a deterministic logarithmic-time access representation for exact queries. We choose the best data structures for representing the labels of each spatial region while building the label list tree. At run time, we further employ a novel query-adaptive culling strategy. While filtering a query down the tree, we prune it successively, and in each node adaptively select the representation that is best suited for evaluating the pruned query, depending on its size. We show an analysis of the efficiency of our approach with several large data sets from connectomics, including a brain scan with more than 13 million labeled segments, and compare our method to conventional culling approaches. Our approach achieves significant reductions in storage size as well as faster query times.