Parallel Separable 3D Convolution for Video and Volumetric Data Understanding
British Machine Vision Conference (BMVC), 2018.
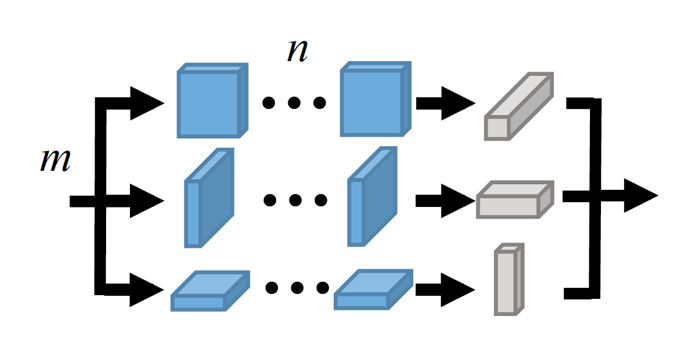
For video and volumetric data understanding, 3D convolution layers are widely used in deep learning, however, at the cost of increasing computation and training time. Recent works seek to replace the 3D convolution layer with convolution blocks, e.g. structured combinations of 2D and 1D convolution layers. In this paper, we propose a novel convolution block, Parallel Separable 3D Convolution (PmSCn), which applies m parallel streams of n 2D and one 1D convolution layers along different dimensions. We first mathematically justify the need of parallel streams (Pm) to replace a single 3D convolution layer through tensor decomposition. Then we jointly replace consecutive 3D convolution layers, common in modern network architectures, with the multiple 2D convolution layers (Cn). Lastly, we empirically show that PmSCn is applicable to different backbone architectures, such as ResNet, DenseNet, and UNet, for different applications, such as video action recognition, MRI brain segmentation, and electron microscopy segmentation. In all three applications, we replace the 3D convolution layers in state-of-theart models with PmSCn and achieve around 14% improvement in test performance and 40% reduction in model size and on average.