Sporthesia: Augmenting Sports Videos Using Natural Language
IEEE Transactions on Visualization and Computer Graphics (IEEE VIS), 2022.
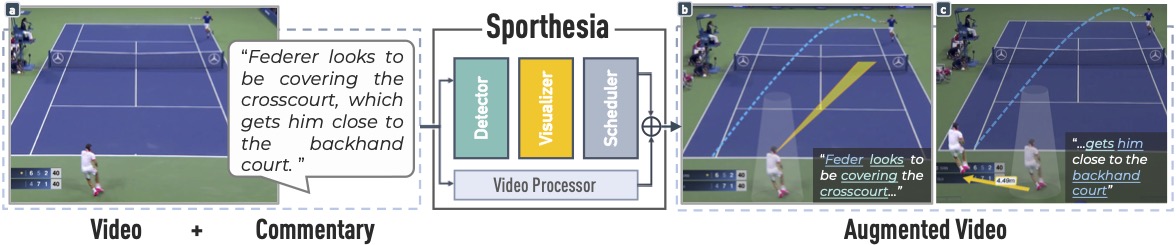
Augmented sports videos, which combine visualizations and video effects to present data in actual scenes, can communicate insights engagingly and thus have been increasingly popular for sports enthusiasts around the world. Yet, creating augmented sports videos remains a challenging task, requiring considerable time and video editing skills. On the other hand, sports insights are often communicated using natural language, such as in commentaries, oral presentations, and articles, but usually lack visual cues. Thus, this work aims to facilitate the creation of augmented sports videos by enabling analysts to directly create visualizations embedded in videos using insights expressed in natural language. To achieve this goal, we propose a three-step approach – 1) detecting visualizable entities in the text, 2) mapping these entities into visualizations, and 3) scheduling these visualizations to play with the video – and analyzed 155 sports video clips and the accompanying commentaries for accomplishing these steps. Informed by our analysis, we have designed and implemented Sporthesia, a proof-of-concept system that takes racket-based sports videos and textual commentaries as the input and outputs augmented videos. We demonstrate Sporthesia’s applicability in two exemplar scenarios, i.e., authoring augmented sports videos using text and augmenting historical sports videos based on auditory comments. A technical evaluation shows that Sporthesia achieves high accuracy (F1-score of 0.9) in detecting visualizable entities in the text. An expert evaluation with eight sports analysts suggests high utility, effectiveness, and satisfaction with our language-driven authoring method and provides insights for future improvement and opportunities.
Acknowledgements
The authors wish to thank the sports experts from Zhejiang University for their time and expertise. A special thanks to Salma Abdel Magid for her beautiful voice and help on the video narration. This research is supported in part by the NSF award III-2107328, NSF award IIS-1901030, NIH award R01HD104969, and the Harvard Physical Sciences and Engineering Accelerator Award.