Trainable convolution filters and their application to face recognition
IEEE transactions on pattern analysis and machine intelligence, 2012.
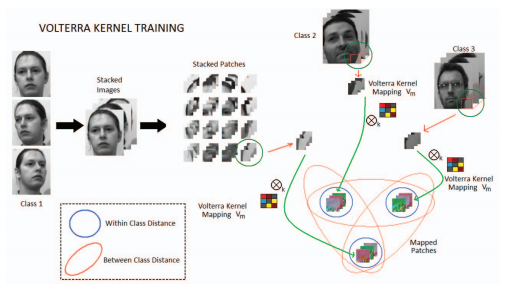
In this paper we present a novel image classification system that is built around a core of trainable filter ensemble that we call Volterra kernel classifiers. Our system treats images as a collection of possibly overlapping patches and is composed of three components: (a) A scheme for single patch classification that seeks a smooth, possibly non-linear, functional mapping of the patches into a range space, where patches of the same class are close to one another, while patches from different classes are far apart – in the L2 sense. This mapping is accomplished using trainable convolution filters (or Volterra kernels) where the convolution kernel can be of any shape or order; (b) Given a corpus of Volterra classifiers with various kernel orders and shapes for each patch, a boosting scheme for automatically selecting the best weighted combination of the classifiers to achieve higher per-patch classification rate; (c) A scheme for aggregating the classification information obtained for each patch via voting for the parent image classification. We demonstrate the effectiveness of the proposed technique using face recognition as an application area and provide extensive experiments on Yale, CMU PIE, Extended Yale B, Multi-PIE and MERL Dome benchmark face datasets. We call the Volterra kernel classifiers applied to face recognition Volterrafaces. We show that our technique, which falls into the broad class of embedding-based face image discrimination methods, consistently outperforms various state-of-the-art methods in the same category.